A intenção desse “guia” é trazer uma visão geral do minimo que você precisa entender sobre redes para começar seus estudos no Hacking.
Claro que Redes é um assunto enorme, então aqui eu vou trazer só uma visão superficial para que a partir daqui você saiba o que procurar para estudar.
Modelo OSI
O modelo OSI (Open Systems Interconnection) é um modelo teórico, padronizado, que usamos para demonstrar as redes de computadores. Na prática, é na verdade o modelo TCP / IP mais compacto no qual a rede do mundo real se baseia; no entanto, o modelo OSI, de muitas maneiras, é mais fácil de se obter uma compreensão inicial.
O modelo OSI tem 7 camadas:
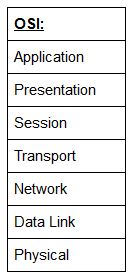
Camada 7: Aplicação
A camada de aplicação do modelo OSI fornece essencialmente opções de rede para programas executados em um computador. Ela funciona quase que exclusivamente com aplicativos, fornecendo uma interface para eles usarem para transmitir dados. Quando os dados são fornecidos à camada de aplicação, eles são transmitidos para a camada de apresentação.
Camada 6: Apresentação
A camada de apresentação recebe dados da camada de aplicação. Esses dados tendem a estar em um formato que o aplicação entende, mas não necessariamente em um formato padronizado que possa ser compreendido pela camada de aplicação no computador receptor. A camada de apresentação traduz os dados em um formato padronizado, além de lidar com qualquer criptografia, compressão ou outras transformações dos dados. Com isso concluído, os dados são passados para a camada de sessão.
Camada 5: Sessão
Quando a camada de sessão recebe os dados formatados corretamente da camada de apresentação, ela verifica se pode estabelecer uma conexão com outro computador através da rede. Se não puder, ele retornará um erro e o processo não prosseguirá. Se uma sessão puder ser estabelecida, é tarefa da camada de sessão mantê-la, bem como cooperar com a camada de sessão do computador remoto para sincronizar as comunicações. A camada de sessão é particularmente importante porque a sessão que ela cria é exclusiva para a comunicação em questão. Isso é o que permite que você faça várias solicitações a diferentes endpoints simultaneamente, sem que todos os dados se misturem (pense em abrir duas guias em um navegador da web ao mesmo tempo)! Quando a camada de sessão registra com sucesso uma conexão entre o host e o computador remoto, os dados são passados para a Camada 4: a camada de transporte.
Camada 4: Transporte
A camada de transporte é uma camada muito interessante que desempenha inúmeras funções importantes. Seu primeiro objetivo é escolher o protocolo pelo qual os dados serão transmitidos. Os dois protocolos mais comuns na camada de transporte são TCP (Transmission Control Protocol) e UDP (User Datagram Protocol); com o TCP, a transmissão é baseada em conexão, o que significa que uma conexão entre os computadores é estabelecida e mantida durante a solicitação. Isso permite uma transmissão confiável, pois a conexão pode ser usada para garantir que todos os pacotes cheguem ao lugar certo. Uma conexão TCP permite que os dois computadores permaneçam em comunicação constante para garantir que os dados sejam enviados a uma velocidade aceitável e que todos os dados perdidos sejam reenviados. Com UDP, o oposto é verdadeiro; pacotes de dados são essencialmente jogados para o computador receptor - se ele não consegue acompanhar, então é um problema (é por isso que uma transmissão de vídeo por algo como o Skype pode ser pixelada se a conexão for ruim). O que isso significa é que o TCP normalmente seria escolhido para situações em que a precisão é favorecida à velocidade (por exemplo, transferência de arquivo ou carregamento de uma página da web), e UDP seria usado em situações onde a velocidade é mais importante (por exemplo, streaming de vídeo).
Com um protocolo selecionado, a camada de transporte divide a transmissão em pequenos pedaços (no TCP são chamados de segmentos, no UDP são chamados de datagramas), o que torna mais fácil transmitir a mensagem com sucesso.
Camada 3: Rede
A camada de rede é responsável por localizar o destino de sua requisição. Por exemplo, a Internet é uma grande rede; quando você deseja solicitar informações de uma página da web, é a camada de rede que obtém o endereço IP da página e descobre o melhor caminho a seguir. Neste estágio, estamos trabalhando com o que é conhecido como endereçamento lógico (ou seja, endereços IP), que ainda são controlados por software. Os endereços lógicos são usados para fornecer ordem às redes, categorizando-as e permitindo-nos classificá-las adequadamente. Atualmente, a forma mais comum de endereçamento lógico é o formato IPV4, com o qual você provavelmente já está familiarizado (ou seja, 192.168.1.1 é um endereço comum para um roteador doméstico).
Camada 2: Enlace
A camada de enlace de dados concentra-se no endereçamento físico da transmissão. Ele recebe um pacote da camada de rede (que inclui o endereço IP do computador remoto) e adiciona o endereço físico (MAC) do endpoint de recebimento. Dentro de cada computador habilitado para rede está uma placa de interface de rede (NIC) que vem com um endereço MAC (Media Access Control) exclusivo para identificá-la.
Os endereços MAC são definidos pelo fabricante e literalmente gravados na placa; eles não podem ser alterados - embora possam ser falsificados. Quando as informações são enviadas através de uma rede, na verdade é o endereço físico que é usado para identificar para onde exatamente enviar as informações.
Além disso, também é função da camada de enlace de dados apresentar os dados em um formato adequado para transmissão.
A camada de enlace também desempenha uma função importante no recebimento de dados, pois verifica as informações recebidas para garantir que não tenham sido corrompidas durante a transmissão, o que pode acontecer quando os dados são transmitidos pela camada 1: a camada física.
Camada 1: Fisica
A camada física está no hardware do computador. É aqui que os pulsos elétricos que constituem a transferência de dados em uma rede são enviados e recebidos. É função da camada física converter os dados binários da transmissão em sinais e transmiti-los pela rede, bem como receber os sinais de entrada e convertê-los de volta em dados binários.
Encapsulamento
Conforme os dados são transmitidos para cada camada do modelo, mais informações contendo detalhes específicos para a camada em questão são adicionadas ao início da transmissão. Como exemplo, o cabeçalho adicionado pela Camada de Rede incluiria coisas como os endereços IP de origem e destino, e o cabeçalho adicionado pela Camada de Transporte incluiria (entre outras coisas) informações específicas do protocolo sendo usado. A camada de enlace de dados também adiciona uma peça no final da transmissão, que é usada para verificar se os dados não foram corrompidos na transmissão; isso também tem o bônus adicional de maior segurança, já que os dados não podem ser interceptados e adulterados sem quebrar o bloco. Todo esse processo é conhecido como encapsulamento; o processo pelo qual os dados podem ser enviados de um computador para outro.
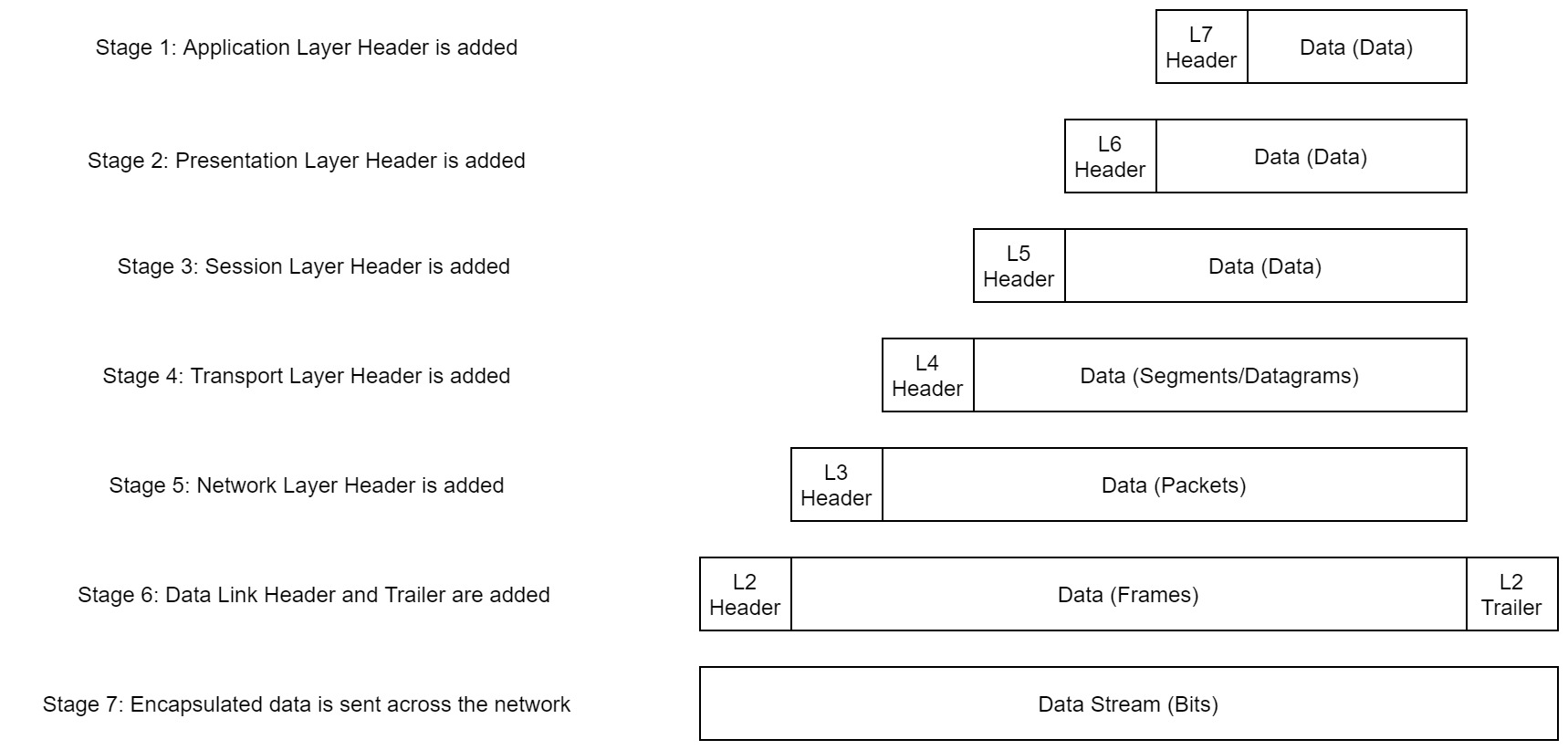
Observe que os dados encapsulados recebem um nome diferente em diferentes etapas do processo. Nas camadas 7,6 e 5, os dados são simplesmente referidos como dados. Na camada de transporte, os dados encapsulados são chamados de segmento ou datagrama (dependendo se TCP ou UDP foi selecionado como protocolo de transmissão). Na camada de rede, os dados são chamados de pacote. Quando o pacote é passado para a camada de enlace de dados, ele se torna um quadro e, no momento em que é transmitido pela rede, o quadro é dividido em bits. Quando a mensagem é recebida pelo segundo computador, ele inverte o processo - começando na camada física e avançando até atingir a camada de aplicação, removendo as informações adicionadas à medida que avançam. Isso é conhecido como desencapsulamento. Assim, você pode pensar nas camadas do modelo OSI como existindo dentro de cada computador com recursos de rede. Embora não seja tão claro na prática, todos os computadores seguem o mesmo processo de encapsulamento para enviar dados e desencapsulamento ao recebê-los.
Os processos de encapsulamento e desencapsulamento são muito importantes - não apenas por causa de seu uso prático, mas também porque nos fornecem um método padronizado de envio de dados. Isso significa que todas as transmissões seguirão consistentemente a mesma metodologia, permitindo que qualquer dispositivo habilitado para rede envie uma solicitação a qualquer outro dispositivo acessível e tenha certeza de que será compreendido - independentemente de serem do mesmo fabricante; usar o mesmo sistema operacional; ou quaisquer outros fatores.
O Modelo TCP/IP
O modelo TCP / IP é, em muitos aspectos, muito semelhante ao modelo OSI. É alguns anos mais velho e serve como base para uma rede do mundo real. O modelo TCP / IP consiste em quatro camadas: Aplicação, Transporte, Internet e Interface de Rede. Entre eles, eles cobrem a mesma gama de funções que as sete camadas do Modelo OSI.
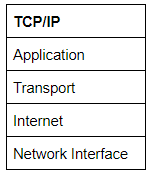
Nota: Algumas fontes recentes dividem o modelo TCP / IP em cinco camadas - dividindo a camada de interface de rede em camadas de Enlace de Dados e Física (como no modelo OSI). Isso é aceito e bem conhecido; no entanto, não é oficialmente definido (ao contrário das quatro camadas originais que são definidas no RFC1122). Você decide qual versão usar - ambas são geralmente consideradas válidas.
Você poderia se perguntar por que nos incomodamos com o modelo OSI se ele não é realmente usado para nada no mundo real. A resposta a essa pergunta é simplesmente que o modelo OSI (por ser menos condensado e mais rígido que o modelo TCP / IP) tende a ser mais fácil para aprender a teoria inicial de rede.
Os dois modelos combinam mais ou menos assim:
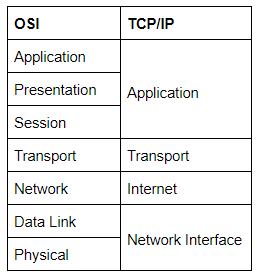
Os processos de encapsulamento e desencapsulamento funcionam exatamente da mesma maneira com o modelo TCP / IP e com o modelo OSI. Em cada camada do modelo TCP / IP, um cabeçalho é adicionado durante o encapsulamento e removido durante o desencapsulamento.
Agora, vamos ao lado prático das coisas.
Um modelo em camadas é ótimo como um auxílio visual - ele nos mostra o processo geral de como os dados podem ser encapsulados e enviados através de uma rede, mas como isso realmente acontece?
Quando falamos sobre TCP / IP, é muito bom pensar em uma tabela com quatro camadas, mas na verdade estamos falando sobre um conjunto de protocolos - conjuntos de regras que definem como uma ação deve ser realizada. O TCP/IP leva o nome dos dois mais importantes: o Transmission Control Protocol - TCP (que abordamos anteriormente no modelo OSI) que controla o fluxo de dados entre dois endpoints, e o Internet Protocol - IP, que controla como os pacotes são endereçados e enviados.
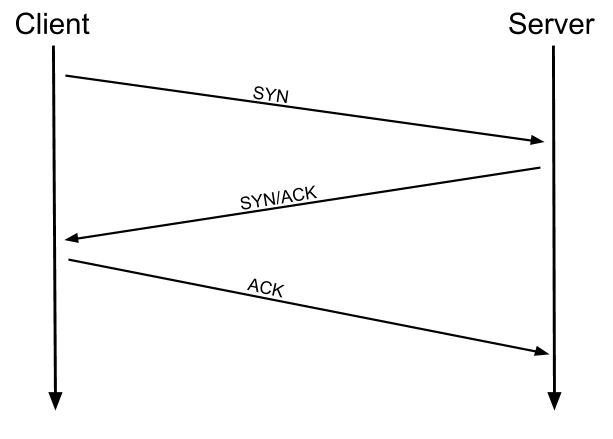
Conforme mencionado anteriormente, o TCP é um protocolo baseado em conexão. Em outras palavras, antes de enviar qualquer dado via TCP, você deve primeiro formar uma conexão estável entre os dois computadores. O processo de formação dessa conexão é chamado de three-way handshake.
Quando você tenta fazer uma conexão, seu computador primeiro envia uma solicitação especial ao servidor remoto indicando que deseja inicializar uma conexão. Essa solicitação contém algo chamado de bit SYN (abreviação de sincronizar), que basicamente faz o primeiro contato ao iniciar o processo de conexão. O servidor responderá então com um pacote contendo o bit SYN, bem como outro bit de “reconhecimento”, denominado ACK. Por fim, seu computador enviará um pacote que contém o bit ACK sozinho, confirmando que a conexão foi configurada com sucesso. Com o three-way handshake concluído com êxito, os dados podem ser transmitidos de forma confiável entre os dois computadores. Quaisquer dados perdidos ou corrompidos na transmissão são reenviados, levando a uma conexão que parece não ter perdas.
História
É importante entender exatamente por que os modelos TCP / IP e OSI foram criados originalmente. No início não havia padronização - diferentes fabricantes seguiam suas próprias metodologias e, consequentemente, sistemas feitos por diferentes fabricantes eram completamente incompatíveis quando se tratava de rede. O modelo TCP / IP foi introduzido pelo DoD americano em 1982 para fornecer um padrão - algo a ser seguido por todos os diferentes fabricantes. Isso resolveu os problemas de inconsistência. Mais tarde, o modelo OSI também foi introduzido pela International Organization for Standardization (ISO); no entanto, ele é usado principalmente como um guia mais abrangente para o aprendizado, já que o modelo TCP / IP ainda é o padrão no qual a rede moderna se baseia.
Ferramentas de Rede
Espero que toda a teoria tenha feito sentido e agora você compreenda os modelos básicos por trás das redes de computadores. Vamos começar a dar uma olhada em algumas das ferramentas de rede de linha de comando que podemos usar em aplicações práticas. Muitas dessas ferramentas funcionam em outros sistemas operacionais, mas por uma questão de simplicidade, presumirei que você esteja executando o Linux
Ping
O comando ping é usado quando queremos testar se uma conexão a um recurso remoto é possível. Normalmente, será um site na Internet, mas também pode ser para um computador em sua rede doméstica se você quiser verificar se está configurado corretamente. Ping funciona usando o protocolo ICMP, que é um dos protocolos TCP/IP um pouco menos conhecidos que foram mencionados anteriormente. O protocolo ICMP funciona na camada de rede do modelo OSI e, portanto, na camada de Internet do modelo TCP/IP. A sintaxe básica para ping é ping [alvo]. Neste exemplo, estamos usando ping para testar se uma conexão de rede com o Google é possível:

Observe que o comando ping, na verdade, retornou o endereço IP do servidor do Google ao qual se conectou, em vez do URL solicitado. Essa é um aplicação secundária útil para ping, pois pode ser usado para determinar o endereço IP do servidor que hospeda um site. Uma das grandes vantagens do ping é que ele é quase onipresente em qualquer dispositivo habilitado para rede. Todos os sistemas operacionais o suportam, e até mesmo a maioria dos dispositivos embarcados pode usar ping!
Traceroute
O Traceroute pode ser usado para mapear o caminho que sua solicitação segue enquanto segue para a máquina de destino.
A Internet é composta de muitos, muitos servidores e endpoints diferentes, todos interligados em rede. Isso significa que, para obter o conteúdo que você realmente deseja, primeiro você precisa passar por vários outros servidores. O Traceroute permite que você veja cada uma dessas conexões - permite que você veja todas as etapas intermediárias entre o seu computador e o recurso que você solicitou. A sintaxe básica para traceroute no Linux é esta: traceroute [destino]
Por padrão, o utilitário traceroute do Windows (tracert) opera usando o mesmo protocolo ICMP que o ping utiliza, e o equivalente Unix opera sobre UDP. Isso pode ser alterado com switches em ambos os casos.

Você pode ver que demorou 13 saltos para ir do meu roteador (_gateway) ao servidor do Google em 216.58.205.46
WHOIS
Nomes de domínio - os salvadores anônimos da Internet.
Você pode imaginar como seria se lembrar do endereço IP de cada site que deseja visitar? Pensamento horrível.
Felizmente, temos domínios.
Um domínio se traduz em um endereço IP para que não precisemos nos lembrar dele (por exemplo, você pode digitar google.com, em vez do endereço IP do Google).
Os domínios são alugados por empresas chamadas de registradores de domínio. Se você quiser um domínio, registre-se em um registrador e, em seguida, alugue o domínio por um determinado período.
O Whois essencialmente permite que você pergunte para quem um nome de domínio está registrado. Na Europa, os dados pessoais são editados; entretanto, em outros lugares, você pode potencialmente obter uma grande quantidade de informações de uma pesquisa whois.
As pesquisas Whois são muito fáceis de realizar. Basta usar whois [domain] para obter uma lista de informações disponíveis sobre o registro de domínio:

Esta é, comparativamente, uma quantidade muito pequena de informação, como muitas vezes pode ser encontrada. Observe que temos o nome de domínio, a empresa que registrou o domínio, a última renovação e quando é o próximo vencimento, e um monte de informações sobre servidores de nomes.
Dig
Falamos sobre domínios no WHOIS - agora vamos falar sobre como eles funcionam.
Você já se perguntou como um URL é convertido em um endereço IP que seu computador pode entender? A resposta é um protocolo TCP / IP chamado DNS (Domain Name System).
No nível mais básico, o DNS permite que solicitemos a um servidor especial o endereço IP do site que estamos tentando acessar. Por exemplo, se fizermos uma solicitação para www.google.com, nosso computador enviará primeiro uma solicitação para um servidor DNS especial (que seu computador já sabe como encontrar). O servidor irá então procurar o endereço IP do Google e o enviará de volta para nós. Nosso computador poderá então enviar a solicitação ao IP do servidor do Google.
Entendendo mais a fundo
Você faz uma solicitação a um site. A primeira coisa que seu computador faz é verificar o cache local para ver se ele já tem um endereço IP armazenado para o site; se isso acontecer, ótimo. Caso contrário, ele passa para a próxima etapa do processo.
Supondo que o endereço ainda não tenha sido encontrado, seu computador enviará uma solicitação ao que é conhecido como servidor DNS recursivo. Eles serão automaticamente conhecidos pelo roteador em sua rede. Muitos provedores de serviços de Internet (ISPs) mantêm seus próprios servidores recursivos, mas empresas como Google e OpenDNS também controlam servidores recursivos. É assim que seu computador sabe automaticamente para onde enviar a solicitação de informações: os detalhes de um servidor DNS recursivo são armazenados em seu roteador. Este servidor também manterá um cache de resultados para domínios populares; entretanto, se o site que você solicitou não estiver armazenado no cache, o servidor recursivo passará a solicitação para um servidor de nomes raiz.
Antes de 2004, havia exatamente 13 servidores DNS raiz no mundo. Hoje em dia existem muitos mais; no entanto, eles ainda podem ser acessados usando os mesmos 13 endereços IP atribuídos aos servidores originais (equilibrados para que você obtenha o servidor mais próximo ao fazer uma solicitação). Os servidores de nomes raiz basicamente controlam os servidores DNS no próximo nível abaixo, escolhendo um apropriado para redirecionar sua solicitação. Esses servidores de nível inferior são chamados de servidores Top-Level Domain.
Os Top-Level Domain (TLD) são divididos em extensões. Então, por exemplo, se você estiver procurando por google.com, sua solicitação será redirecionada para um servidor TLD que manipula domínios .com. Se você estiver procurando por bbc.co.uk, sua solicitação será redirecionada para um servidor TLD que lida com domínios .co.uk. Assim como acontece com os servidores de nomes raiz, os servidores TLD controlam o próximo nível abaixo: Servidores autoritativos. Quando um servidor TLD recebe sua solicitação de informações, o servidor a transmite a um servidor de nomes Autoritativo apropriado.
Servidores autoritativos são usados para armazenar registros DNS para domínios diretamente. Em outras palavras, todos os domínios do mundo terão seus registros DNS armazenados em um servidor de nomes autoritativo em algum lugar; eles são a fonte das informações. Quando sua solicitação chegar ao servidor de nomes autoritativo para o domínio que você está consultando, ele enviará as informações relevantes de volta para você, permitindo que seu computador se conecte ao endereço IP por trás do domínio que você solicitou.
Quando você visita um site em seu navegador, tudo acontece automaticamente, mas também podemos fazer isso manualmente com uma ferramenta chamada dig. Como ping e traceroute, dig deve vir instalado automaticamente em sistemas Linux.
Dig nos permite consultar manualmente servidores DNS recursivos de nossa escolha para obter informações sobre domínios: dig [domain] @ [dns-server-ip]
É uma ferramenta muito útil para solução de problemas de rede.

Isso é muita informação. Dedicar algum tempo para aprender o que tudo isso significa é uma ideia muito boa. Em resumo, essa informação está nos dizendo que enviamos uma consulta e com sucesso (ou seja, sem erros) recebemos uma resposta completa - que, como esperado, contém o endereço IP do nome de domínio que consultamos.
Outra informação interessante que o dig nos fornece é o TTL (Time To Live) do registro DNS consultado. Conforme mencionado anteriormente, quando seu computador consulta um nome de domínio, ele armazena os resultados em seu cache local. O TTL do registro informa ao seu computador quando parar de considerar o registro como válido - ou seja, quando ele deve solicitar os dados novamente, em vez de depender da cópia em cache.
O TTL pode ser encontrado na segunda coluna da seção de respostas:

É importante lembrar que o TTL (no contexto do cache DNS) é medido em segundos, portanto, o registro no exemplo irá expirar em dois minutos e trinta e sete segundos.
Serviços de rede
SMB
SMB - Server Message Block Protocol - é um protocolo de comunicação cliente-servidor usado para compartilhar o acesso a arquivos, impressoras, portas seriais e outros recursos em uma rede.
Os servidores disponibilizam sistemas de arquivos e outros recursos (impressoras, canais nomeados, APIs) aos clientes na rede. Os computadores clientes podem ter seus próprios discos rígidos, e também acessar os sistemas de arquivos e impressoras compartilhados nos servidores.
O protocolo SMB é conhecido como protocolo de solicitação de resposta, o que significa que ele transmite várias mensagens entre o cliente e o servidor para estabelecer uma conexão. Os clientes se conectam a servidores usando TCP / IP (na verdade, NetBIOS sobre TCP / IP conforme especificado em RFC1001 e RFC1002), NetBEUI ou IPX / SPX.
Como o SMB funciona?

Depois de estabelecer uma conexão, os clientes podem enviar comandos (SMBs) para o servidor que lhes permite acessar compartilhamentos, abrir arquivos, ler e gravar arquivos e, geralmente, fazer todo o tipo de coisas que você deseja fazer com um sistema de arquivos. No entanto, no caso de SMB, essas coisas são feitas pela rede.
Enumerando SMB
Enumeração é o processo de coleta de informações sobre um alvo para encontrar vetores de ataque em potencial e ajudar na exploração.
Esse processo é essencial para o sucesso de um ataque, pois perder tempo com exploits que não funcionam ou podem travar o sistema pode ser um desperdício de energia. A enumeração pode ser usada para reunir nomes de usuário, senhas, informações de rede, nomes de host, dados de aplicativos, serviços ou qualquer outra informação que possa ser valiosa para um invasor.
Normalmente, existem unidades de compartilhamento SMB em um servidor que podem ser conectadas e usadas para visualizar ou transferir arquivos. O SMB geralmente pode ser um ótimo ponto de partida para um invasor que procura descobrir informações confidenciais - você ficaria surpreso com o que às vezes está incluído nesses compartilhamentos.
Port Scan
A primeira etapa da enumeração é conduzir uma varredura de porta, para descobrir o máximo de informações possível sobre os serviços, aplicativos, estrutura e sistema operacional da máquina de destino.
Enum4Linux
Enum4linux é uma ferramenta usada para enumerar compartilhamentos SMB em sistemas Windows e Linux. É basicamente um invólucro em torno das ferramentas do pacote Samba e facilita a extração rápida de informações do destino relativas ao SMB. Ele é instalado por padrão no Parrot e Kali, no entanto, se você precisar instalá-lo, pode fazê-lo a partir do github oficial.
A sintaxe do Enum4Linux é agradável e simples: enum4linux [opção] ip
TAG FUNÇÃO
-U obter lista de usuários
-M obter lista de máquinas
-N obter dump da lista de nomes (diferente de -U e-M)
-S obter lista de compartilhamento
-P obter informações de política de senha
-G obter grupo e lista de membros
-A todos os itens acima (enumeração básica completa)
Telnet
Telnet é um protocolo de aplicativo que permite que você, com o uso de um cliente telnet, se conecte e execute comandos em uma máquina remota que hospeda um servidor telnet.
O cliente telnet estabelecerá uma conexão com o servidor. O cliente então se tornará um terminal virtual - permitindo que você interaja com o host remoto.
Substituição
O Telnet envia todas as mensagens em texto não criptografado e não possui mecanismos de segurança específicos. Portanto, em muitos aplicativos e serviços, o Telnet foi substituído por SSH na maioria das implementações.
Como o Telnet funciona?
O usuário se conecta ao servidor usando o protocolo Telnet, o que significa inserir “telnet” em um prompt de comando. O usuário então executa comandos no servidor usando comandos Telnet específicos no prompt Telnet. Você pode se conectar a um servidor telnet com a seguinte sintaxe: telnet [ip] [porta]
Enumerando Telnet
A enumeração pode ser a chave na exploração de um serviço de rede mal configurado. No entanto, vulnerabilidades que podem ser potencialmente triviais de explorar nem sempre surgem sobre nós. Por esse motivo, especialmente quando se trata de enumerar os serviços de rede, precisamos ser minuciosos em nosso método.
Port Scan
O Scan deve ser feito da forma que costumamos fazer, uma varredura de porta, para descobrir o máximo de informações que pudermos sobre os serviços, aplicativos, estrutura e sistema operacional da máquina de destino. É importante fazer um scan completo, e não só nas primeiras 1000 portas como no padrão do nmap, muitas vezes o Telnet está disponível mas funciona em algumas portas bem altas.
FTP
O protocolo de transferência de arquivos (FTP) é, como o nome sugere, um protocolo usado para permitir a transferência remota de arquivos em uma rede. Ele usa um modelo cliente-servidor para fazer isso e - como veremos mais tarde - retransmite comandos e dados de uma maneira muito eficiente.
Como o FTP funciona?
Uma sessão de FTP típica opera usando dois canais:
* um canal de comando (às vezes chamado de controle)
* um canal de dados.
Como seus nomes indicam, o canal de comando é usado para transmitir comandos, bem como respostas a esses comandos, enquanto o canal de dados é usado para transferir dados.
O FTP opera usando um protocolo cliente-servidor. O cliente inicia uma conexão com o servidor, o servidor valida todas as credenciais de login fornecidas e, em seguida, abre a sessão.
Enquanto a sessão está aberta, o cliente pode executar comandos FTP no servidor.
Ativo vs Passivo
O servidor FTP pode suportar conexões ativas ou passivas, ou ambas.
* Em uma conexão FTP ativa, o cliente abre uma porta e escuta. O servidor é necessário para se conectar ativamente a ele.
* Em uma conexão FTP passiva, o servidor abre uma porta e escuta (passivamente) e o cliente se conecta a ela.
Essa separação de informações de comando e dados em canais separados é uma forma de enviar comandos ao servidor sem ter que esperar que a transferência de dados atual termine. Se os dois canais estivessem interligados, você só poderia inserir comandos entre as transferências de dados, o que não seria eficiente para transferências de arquivos grandes ou conexões lentas com a Internet.
Enumerando FTP
Acho que não preciso explicar mais como a enumeração é a chave ao atacar serviços e protocolos de rede. Se você travar usando qualquer ferramenta, você sempre pode usar ferramenta [-h / -help / –help] para descobrir mais sobre sua função e sintaxe. Da mesma forma, as páginas do manual são extremamente úteis para esse propósito. Eles podem ser alcançados usando man [ferramenta] .
Método
Ao explorar um login de FTP é uma boa opção tentar um login anônimo, para ver quais arquivos podemos acessar - e se eles contêm alguma informação que possa nos permitir abrir um shell no sistema. Este é um caminho comum em desafios de CTF e imita uma implementação descuidada da vida real de servidores FTP.
Recursos
Para fazer login em um servidor FTP, precisamos ter certeza de que um cliente FTP está instalado no sistema. Deve haver um instalado por padrão na maioria dos sistemas operacionais Linux, como Kali ou Parrot OS. Você pode testar se há um digitando ftp no console. Se você for levado a um prompt que diz: ftp>, então você tem um cliente FTP funcionando em seu sistema. Caso contrário, é uma simples questão de usar sudo apt install ftp para instalar um.
É importante notar que algumas versões vulneráveis do in.ftpd e algumas outras variantes do servidor FTP retornam respostas diferentes ao comando cwd para diretórios pessoais existentes e não existentes. Isso pode ser explorado porque você pode emitir comandos cwd antes da autenticação e, se houver um diretório inicial, é mais do que provável que haja uma conta de usuário para acompanhá-lo. Embora esse bug seja encontrado principalmente em sistemas legados, vale a pena conhecê-lo, como uma forma de explorar o FTP.
Esta vulnerabilidade está documentada em: https://www.exploit-db.com/exploits/20745
NFS
NFS significa “Network File System” e permite que um sistema compartilhe diretórios e arquivos com outras pessoas em uma rede. Ao usar o NFS, os usuários e programas podem acessar arquivos em sistemas remotos quase como se fossem arquivos locais. Ele faz isso montando todo ou uma parte de um sistema de arquivos em um servidor. A parte do sistema de arquivos que é montada pode ser acessada por clientes com quaisquer privilégios atribuídos a cada arquivo.
Como o NFS funciona?
Não precisamos entender a troca técnica em muitos detalhes para sermos capazes de explorar o NFS de forma eficaz - no entanto, se isso for algo do seu interesse, eu recomendaria este recurso: https://docs.oracle.com/cd/E19683-01/816-4882/6mb2ipq7l/index.html
Primeiro, o cliente solicitará a montagem de um diretório de um host remoto em um diretório local, como se estivesse montando um dispositivo físico. O serviço de montagem atuará então para se conectar ao daemon de montagem usando RPC.
O servidor verifica se o usuário tem permissão para montar qualquer diretório solicitado. Em seguida, ele retornará um identificador de arquivo que identifica exclusivamente cada arquivo e diretório que está no servidor.
Se alguém deseja acessar um arquivo usando NFS, uma chamada RPC é feita para NFSD (o daemon NFS) no servidor. Esta chamada usa parâmetros como:
* O identificador de arquivo
* O nome do arquivo a ser acessado
* O usuário, ID de usuário
* O ID do grupo do usuário
Eles são usados para determinar os direitos de acesso ao arquivo especificado. Isso é o que controla as permissões do usuário, leitura e gravação de arquivos.
Usando o protocolo NFS, você pode transferir arquivos entre computadores que executam Windows e outros sistemas operacionais não Windows, como Linux, MacOS ou UNIX.
Um computador executando o Windows Server pode atuar como um servidor de arquivos NFS para outros computadores clientes não Windows. Da mesma forma, o NFS permite que um computador baseado no Windows que executa o Windows Server acesse arquivos armazenados em um servidor NFS não Windows.
Mais informações
Aqui estão alguns recursos que explicam a implementação técnica e o funcionamento do NFS com mais detalhes do que os que cobri aqui.
https://www.datto.com/library/what-is-nfs-file-share
http://nfs.sourceforge.net/
https://wiki.archlinux.org/index.php/NFS
Enumerando NFS
Requisitos
Para fazer uma enumeração mais avançada do servidor NFS e compartilhamentos, vamos precisar de algumas ferramentas. O primeiro deles é a chave para interagir com qualquer compartilhamento NFS de sua máquina local: nfs-common.
NFS-Common
É importante ter este pacote instalado em qualquer máquina que use NFS, seja como cliente ou servidor. Inclui programas como: lockd, statd, showmount, nfsstat, gssd, idmapd e mount.nfs. Primeiramente, as funções que mais chamam atenção são: “showmount” e “mount.nfs”, pois eles serão mais úteis para nós quando se trata de extrair informações do compartilhamento NFS. Se desejar obter mais informações sobre este pacote, sinta-se à vontade para ler: https://packages.ubuntu.com/xenial/nfs-common.
Você pode instalar o nfs-common usando sudo apt install nfs-common, ele faz parte dos repositórios padrão para a maioria das distribuições Linux, como o Kali
Montando compartilhamentos NFS
O sistema do seu cliente precisa de um diretório onde todo o conteúdo compartilhado pelo servidor host na pasta de exportação possa ser acessado. Você pode criar esta pasta em qualquer lugar do seu sistema. Depois de criar este ponto de montagem, você pode usar o comando “mount” para conectar o compartilhamento NFS ao ponto de montagem em sua máquina, assim:
sudo mount -t nfs IP:share /tmp/mount/ -nolock
TAG FUNÇÃO
sudo Executar como root
mount Execute o comando de montagem
-t nfs Tipo de dispositivo a ser montado e, em seguida, especificando que é NFS
IP:share O endereço IP do servidor NFS e o nome do compartilhamento que desejamos montar
-nolock Especifica para não usar o bloqueio de NLM
SMTP
SMTP significa “Simple Mail Transfer Protocol”. É utilizado para gerenciar o envio de e-mails. Para oferecer suporte aos serviços de e-mail, é necessário um par de protocolos, composto de SMTP e POP/IMAP. Juntos, eles permitem que o usuário envie mensagens de saída e recupere mensagens de entrada, respectivamente.
O servidor SMTP executa três funções básicas:
* Ele verifica quem está enviando emails por meio do servidor SMTP.
* Ele envia o e-mail de saída
* Se o e-mail de saída não puder ser entregue, ele enviará a mensagem de volta ao remetente
A maioria das pessoas terá encontrado SMTP ao configurar um novo endereço de e-mail em alguns clientes de e-mail de terceiros, como Thunderbird; como quando você configura um novo cliente de e-mail, você precisará definir a configuração do servidor SMTP para enviar e-mails de saída.
POP e IMAP
POP, ou “Post Office Protocol” e IMAP, “Internet Message Access Protocol”, são protocolos de e-mail responsáveis pela transferência de e-mail entre um cliente e um servidor de e-mail. A principal diferença está na abordagem mais simplista do POP de baixar a caixa de entrada do servidor de e-mail para o cliente. Onde IMAP irá sincronizar a caixa de entrada atual, com novos e-mails no servidor, baixando qualquer coisa nova. Isso significa que as alterações na caixa de entrada feitas em um computador, via IMAP, persistirão se você sincronizar a caixa de entrada de outro computador. O servidor POP/IMAP é responsável por realizar este processo.
Como o SMTP funciona?
A entrega de e-mail funciona da mesma forma que o sistema físico de entrega dos correios. O usuário fornecerá o e-mail (uma carta) e um serviço (o serviço de entrega postal) e, por meio de uma série de etapas, o entregará na caixa de entrada do destinatário (caixa de correio). A função do servidor SMTP neste serviço, é atuar como escritório de triagem, o e-mail (carta) é recolhido e enviado para este servidor, que o encaminha para o destinatário.
Podemos mapear a jornada de um e-mail do seu computador até o destinatário da seguinte maneira:

1 - O agente de usuário de email, que é seu cliente de email ou um programa externo. conecta-se ao servidor SMTP de seu domínio, por exemplo, smtp.google.com. Isso inicia o handshake SMTP. Essa conexão funciona pela porta SMTP - que geralmente é 25. Depois que essas conexões forem feitas e validadas, a sessão SMTP é iniciada.
2 - O processo de envio de e-mail pode agora começar. O cliente primeiro envia o remetente e o endereço de e-mail do destinatário - o corpo do e-mail e todos os anexos, para o servidor.
3 - O servidor SMTP então verifica se o nome de domínio do destinatário e do remetente é o mesmo.
4 - O servidor SMTP do remetente fará uma conexão com o servidor SMTP do destinatário antes de retransmitir o e-mail. Se o servidor do destinatário não puder ser acessado ou não estiver disponível, o e-mail é colocado em uma fila SMTP.
5 - Em seguida, o servidor SMTP do destinatário verificará o e-mail recebido. Ele faz isso verificando se o domínio e o nome de usuário foram reconhecidos. O servidor irá então encaminhar o e-mail para o servidor POP ou IMAP, conforme mostrado no diagrama acima.
6 - O e-mail aparecerá na caixa de entrada do destinatário.
Esta é uma versão muito simplificada do processo e há muitos subprotocolos, comunicações e detalhes que não foram incluídos. Se você deseja aprender mais sobre este tópico, esta é uma análise com uma linguagem mais amigável para ler os detalhes técnicos: https://computer.howstuffworks.com/e-mail-messaging/email3.htm
O software do servidor SMTP está prontamente disponível nas plataformas de servidor Windows, com muitas outras variantes do SMTP disponíveis para execução no Linux.
Mais informações
Aqui está um recurso que explica a implementação técnica e o funcionamento do SMTP em mais detalhes do que os que eu cobri aqui.
https://www.afternerd.com/blog/smtp/
Enumerando SMTP
Enumerando detalhes do servidor
Servidores de e-mail mal configurados ou vulneráveis geralmente podem fornecer uma base inicial em uma rede, mas antes de lançar um ataque, queremos uma impressão digital do servidor para tornar nosso direcionamento o mais preciso possível. Podemos usar o módulo smtp_version no MetaSploit para fazer isso. Como o próprio nome indica, ele fará a varredura em uma série de endereços IP e determinará a versão de todos os servidores de e-mail que encontrar.
Enumerando usuários de SMTP
O serviço SMTP possui dois comandos internos que permitem a enumeração de usuários: VRFY (confirmando os nomes de usuários válidos) e EXPN que revela o endereço real dos aliases do usuário e listas de e-mail (listas de mala direta). Usando esses comandos SMTP, podemos revelar uma lista de usuários válidos
Podemos fazer isso manualmente, por meio de uma conexão telnet - no entanto, o Metasploit pode ajudar novamente, fornecendo um módulo útil apropriadamente chamado smtp_enum que fará o trabalho braçal para nós! Usar o módulo é uma simples questão de alimentá-lo com um host ou intervalo de hosts para verificar e uma lista de palavras contendo nomes de usuário para enumerar.
Alternativas
É importante notar que essa técnica de enumeração funcionará para a maioria das configurações SMTP; no entanto, existem outras ferramentas não metasploit, como smtp-user-enum, que funcionam ainda melhor para enumerar contas de usuário no nível do sistema operacional no Solaris por meio do serviço SMTP. A enumeração é realizada inspecionando as respostas aos comandos VRFY, EXPN e RCPT TO.
MySQL
Em sua definição mais simples, MySQL é um sistema de gerenciamento de banco de dados relacional (RDBMS) baseado em Structured Query Language (SQL). Muitas siglas? Vamos decompô-lo:
Banco de dados
Um banco de dados é simplesmente uma coleção persistente e organizada de dados estruturados
RDBMS
Um software ou serviço usado para criar e gerenciar bancos de dados com base em um modelo relacional. A palavra “relacional” significa apenas que os dados armazenados no conjunto de dados são organizados como tabelas. Cada tabela se relaciona de alguma forma com a “chave primária” ou outros fatores de “chave” uns dos outros.
SQL
MYSQL é apenas um nome de marca para uma das implementações de software RDBMS mais populares. Como sabemos, ele usa um modelo cliente-servidor. Mas como o cliente e o servidor se comunicam? Eles usam uma linguagem, especificamente a Structured Query Language (SQL).
Muitos outros produtos, como PostgreSQL e Microsoft SQL server, contêm a palavra SQL. Isso também significa que este é um produto que utiliza a sintaxe da Structured Query Language.
Como o MySQL funciona?
O MySQL, como um RDBMS, é composto pelos programas servidores e utilitários que auxiliam na administração dos bancos de dados MySQL.
O servidor lida com todas as instruções do banco de dados, como criação, edição e acesso aos dados. Ele recebe e gerencia essas solicitações e se comunica usando o protocolo MySQL. Todo esse processo pode ser dividido nestas etapas:
1 - O MySQL cria um banco de dados para armazenamento e manipulação de dados, definindo o relacionamento de cada tabela.
2 - Os clientes fazem solicitações fazendo declarações específicas em SQL.
3 - O servidor responderá ao cliente com todas as informações solicitadas.
O MySQL pode ser executado em várias plataformas, seja Linux ou Windows. É comumente usado como um banco de dados de back-end para muitos sites importantes e constitui um componente essencial da pilha LAMP, que inclui: Linux, Apache, MySQL e PHP.
Mais informações
Aqui estão alguns recursos que explicam a implementação técnica e o funcionamento do MySQL com mais detalhes do que os que cobri aqui:
https://dev.mysql.com/doc/dev/mysql-server/latest/PAGE_SQL_EXECUTION.html
https://www.w3schools.com/php/php_mysql_intro.asp
Enumerando MySQL
Provavelmente, o MySQL não será o primeiro ponto que você vai abordar para obter informações iniciais sobre o servidor. Você pode tentar usar a força bruta de senhas de conta padrão se realmente não tiver nenhuma outra informação; no entanto, na maioria dos cenários do CTF, é improvável que esse seja o caminho que você deve seguir.
Normalmente, você terá obtido algumas credenciais iniciais enumerando outros serviços que poderá usar para enumerar e explorar o serviço MySQL.